Full papers
On the origin of the genetic code
2023 年 98 巻 1 号 p. 9-24

詳細
2023 年 98 巻 1 号 p. 9-24
Mechanisms underlying how the genetic code was generated by Darwinian selection have remained elusive since the code was cracked in 1965. Here, I propose a hypothesis on the emergence of the genetic code and predict that its emergence was driven by sequential distinct selective pressures. According to the hypothesis, aminoacyl-RNAs for Glu, Asp, Lys, Tyr, His, Arg, Cys and Ser were first selected as cartridge-type subunits of three-subunit ribozymes. Aminoacyl-RNA subunits acting as cofactors were accommodated by the proto P-site of the large subunit of ribozymes. Importantly, I predict that there was no direct relationship between amino acids and codon and anticodon pairs. Duplication of the proto P-site could have created the proto A-site, enabling multi-subunit ribozymes to simultaneously interact with two-cartridge-type aminoacyl-RNA subunits. Random insertion of two cartridges would have instantly abolished enzymatic activity of multi-subunit ribozymes. On the other hand, if two tandemly aligned pairs of codons and anticodons specify two cartridges, dozens of different active pockets in multi-subunit ribozymes would have rapidly emerged, leading to the rise of extant organisms’ metabolic pathways. The strong driving force of Darwinian selection described here could have created the primary genetic code for catalytic amino acids. Evolution of the protein translation system and events leading to the expansion of the genetic code until the time it was “frozen” are presented in detail.
The concept of evolution (Cairns-Smith, 1985) is applied toward understanding how the last universal common ancestor (LUCA, symbolized as an arch made of gray rocks) was generated (Fig. 1A(a), (b), (c)). The LUCA (Fig. 1A(c)) may have emerged via an intermediate state (the gray arch supported by “red rocks”) (Fig. 1A(b)) rather than in a holistic manner (Fig. 1A(a)). The problem is that the symbolic red rocks (Fig. 1A(b)), which acted in the pre-LUCA era, have been almost non-existent since ~3.8–3.9 billion years ago (Fig. 1A(c)). Phylogenetic analysis of all organisms on our planet revealed the past existence of the LUCA (Fig. 1A(d)). Remarkably, the conceptual phylogenetic tree drawn by Darwin (Ragan, 2009) (Fig. 1A(e)) is similar to the phylogenetic tree of all organisms drawn by Woese (Balch et al., 1977; Woese, 2000).
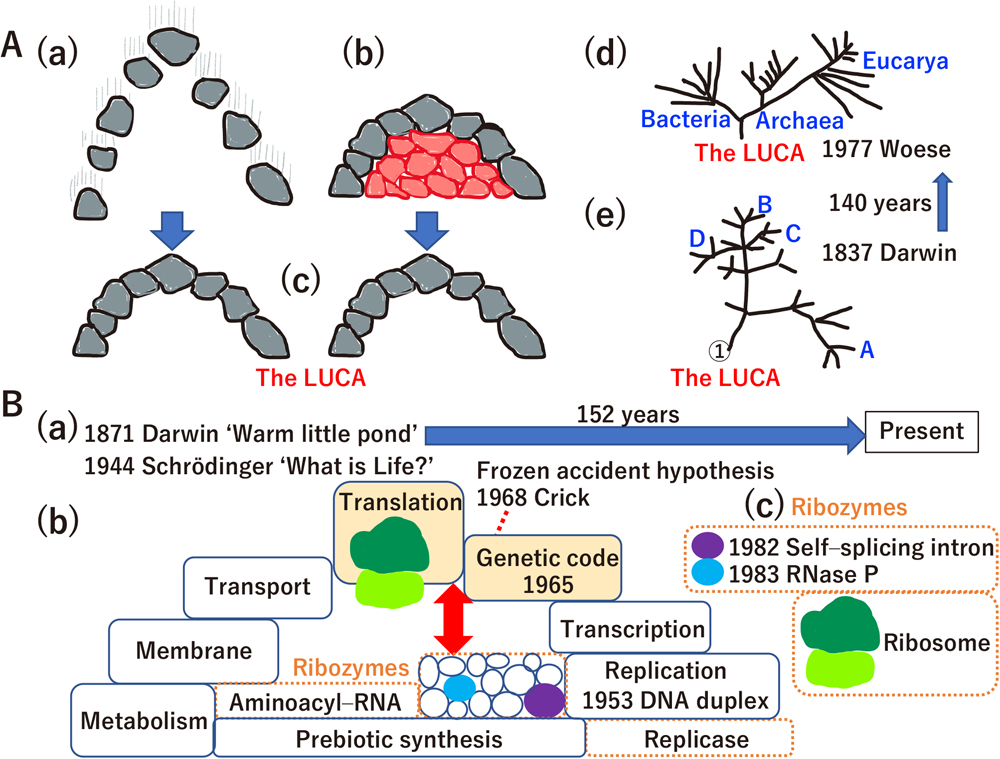
The unsolved hard problem of biology. (A) A brief history of evolutionary biology. (a) Holistic evolution, (b) evolution mediated by an extinct intermediate (i.e., symbolic “red rocks”) and (c) organisms, such as the LUCA. The original concept for the transition from (a) to (c) or from (a) to (b) during evolutionary processes was presented by Cairns-Smith (1985), who proposed that replication of biomolecules in the prebiotic era (the arch made of gray rocks) did not evolve in a holistic manner (expressed by the vertical streaks associated with the gray rocks) (a); rather, a clay crystal (the red rocks) acted as a template for the replication of biomolecules (the red sheltered structures made of red rocks support construction of the arch) (b). Finally, complex biomolecules undertook “genetic takeover” (the red rocks became unnecessary to support the gray arch, and then finally disappeared) (c). (d) The LUCA phylogenetic tree based on rRNA sequence by Woese (2000). (e) A phylogenetic tree sketched by Darwin in his notebook (Ragan, 2009). All original figures presented in panels (a)–(e) are re-drawn. (B) A brief history of the origin of life. (a) Charles Darwin was the first to scientifically describe the origin of life. In his letter to his friend Joseph Hooker, there was a description of a “warm little pond”. “What is Life?” is the title of a book written by Erwin Schrödinger that depicts the physical view of biology. (b) Schematic view of the LUCA. The LUCA was a complex organism supported by a variety of molecules, including DNA, RNA, proteins, lipids and hundreds of metabolites (Mirkin et al., 2003). Most of these biomolecules can be prebiotically synthesized in vitro (large block in the base of the arch), as described in the text. Each block of the arch (just like the gray rocks in 1A(a–c)) represents a component of the LUCA (the complete arch). Francis Crick proposed the “frozen accident theory” on the genetic code in 1968 (the red dashed line), after it was cracked in 1965. The origins of translation, the ribosome and the genetic code are not yet solved. (c) The quest for the red sheltered structures made by the red rocks in 1A(b) supporting the genetic code and translation (the gray arch in 1A(a–c)) revealed the few remaining red rocks (self-splicing introns, RNase P and peptidyl transferase activity of the ribosome) as molecular fossils of the extinct intermediates shown in 1A(b). Besides natural ribozymes (1B(c)), a variety of ribozymes, including replicases and aminoacyl-RNA synthetases, are selected in vitro to reconstruct extinct species (encircled by dashed orange rectangles in 1B(b)). However, it is still difficult to explain how the remaining ribozymes supported the translation system and genetic code in the pre-LUCA era. The bidirectional red arrow in 1B(b) expresses such difficulty as a large gap.
The emergence of the LUCA at 3.8–3.9 billion years ago was first considered by Darwin as a “warm little pond” concept (Fig. 1B(a)) (Follmann and Brownson, 2009). Although it has been a century and a half since Darwin’s “warm little pond” proposal, the key red rocks have remained elusive until today. “What is Life?” (Schrödinger, 1944) inspired many scientists (Fig. 1B(b)), leading to the discovery of double-stranded DNA (Watson and Crick, 1953) and the genetic code (Nirenberg, 2004) (Fig. 1B(b)). Reconstruction of the LUCA by phylogenetic analyses revealed that the LUCA was a complicated organism just like extant organisms (Koonin, 2003; Tuller et al., 2010). The translation system and genetic code were completed upon the emergence of the LUCA (Fig. 1B(b)). In the “frozen accident theory”, Crick (1968) proposed that the genetic code was frozen before the birth of the LUCA. Filling the red arrow in Fig. 1B(b) – which represents the difficulty of understanding the origin of the genetic code and translation system – based on our current knowledges of ribozymes (Fig. 1B(b)) is one important central question in biology. The difficulty in addressing this question was raised in previous papers. For example, Crick et al. (1976) noted that “the origin of protein synthesis is a notoriously difficult problem”, and Wolf and Koonin (2007) stated that “This is one of the most fundamental and hardest problems in all biology.” Understanding how the genetic code emerged is equivalent to solving the evolution of the translation system and the LUCA itself.
Searching for the red rocks and red arrow led to the discovery of ribozymes (Fig. 1B(c)) (Kruger et al., 1982; Guerrier-Takada et al., 1983) and the invention of artificially made ribozymes, including replicases (Hager et al., 1996; Chen et al., 2007), leading to the “RNA world” concept (Gilbert, 1986). Prebiotic synthesis, a concept raised by Haldane and Oparin (Haldane, 1929; Oparin, 1938), was experimentally demonstrated by Miller (1953). Through prebiotic synthesis, amino acids were made in a flask from water, methane, ammonia and hydrogen. Since Miller’s experiments, most compounds in extant cells, including all nucleotides for RNA and DNA, RNA polymers, all amino acids for protein synthesis, polypeptides, aminoacyl-RNA, peptidyl-RNA, a variety of metabolites, and all extant cofactors, have been prebiotically synthesized in vitro (Keller et al., 2014; Canavelli et al., 2019; Kruse et al., 2020; Kirschning, 2021; Müller et al., 2022; Zhang et al., 2022). Amino acids and nucleotides are detected in a variety of meteorites (Oba et al., 2022), and oceanic meteorite impacts during the early Earth period are known to have resulted in a variety of biomolecules (Furukawa et al., 2009), suggesting that massive amounts of prebiotic material were directly and/or indirectly the consequence of events occurring outside the planet. Instead of a “warm little pond”, submarine alkaline vents are proposed to be the best candidate for the origin of prebiotic synthesis and the birth of the LUCA (Branscomb and Russell, 2019). Since 1871, tremendous effort has been devoted to discovering the red rocks and red arrow. However, the main components that contribute the red rocks and red arrow concept in our planet and the universe remain a mystery.
The aim of this study is to introduce new ideas and hypotheses about the origin of the genetic code. Here, I propose that key components of the red rocks and red arrow in Fig. 1 are one-cartridge and two-cartridge ribozymes (see Fig. 12). I hypothesize that the emergence of the genetic code was driven by eight sequential distinct driving forces of traditional Darwinian selection (see Figs. 3, 5, 8, 9, 10B, 10C and 11). Genetics based on both genotype and phenotype began at the first wave of generating the genetic code (see Figs. 4 and 5). The possible whole process leading to the generation of the genetic code is presented.
Since Miller’s experiments, amino acids, polypeptides, nucleotides, polynucleotides, aminoacyl-RNA and peptidyl-RNA have been synthesized under prebiotic conditions (Fig. 2A). Ribozymes and DNAzymes have been generated by in vitro artificial selection (Fig. 2A). It is worth noting that the serine-histidine (Ser-His) dipeptide catalyzes hydrolase activity, peptide formation and phosphodiester bond formation (Wieczorek et al., 2017). Histidine alone stimulates DNAzyme activity (Roth and Breaker, 1998). Peptide-dependent ribozymes are also generated (Robertson et al., 2004). Peptides stimulate RNA-based replicases (Tagami et al., 2017; Li et al., 2022). Moreover, RNA–amino acid conjugates have enzymatic activity (Radakovic et al., 2022). Taking these features together, ribozymes should functionally interact with amino acids, peptides, aminoacyl-RNA and peptidyl-RNA.
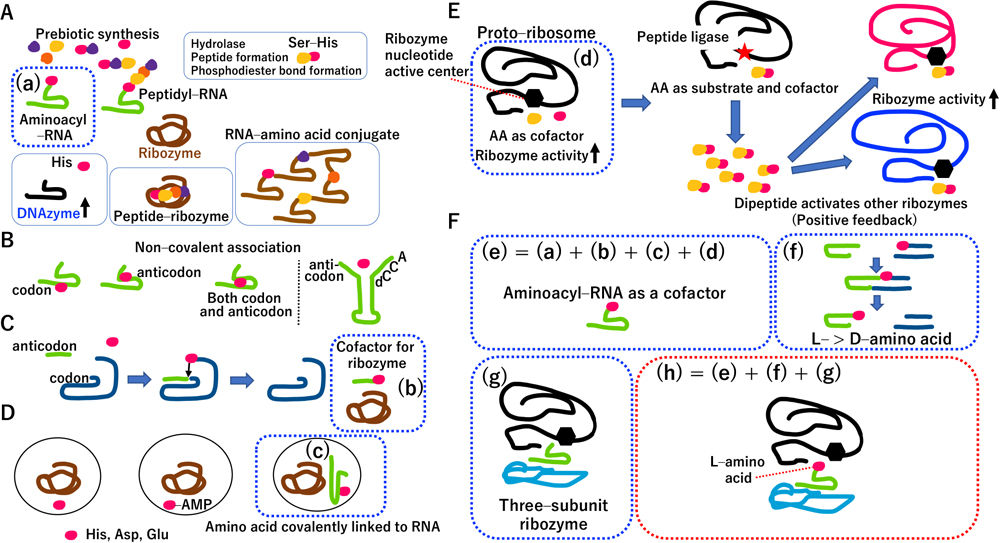
Multi-subunit ribozyme containing an aminoacyl-RNA subunit. (A) Interplay between RNA and amino acids (or peptides). Colored circles represent a single amino acid. Aminoacyl-RNA is a kind of RNA conjugate. The carboxy group (alpha-carbon) of the amino acid is covalently linked to an RNA molecule, forming aminoacyl-RNA. On the other hand, any carboxy group, amino group or hydroxy group of an amino acid could form a covalent link with RNA, resulting in “RNA–amino acid conjugates”. (B) Left panel: direct RNA-templating (DRT) hypothesis, Right panel: complex of four nucleotides (C4N) hypothesis. (C) The coding coenzyme handle (CCH) hypothesis. (D) Another version of the CCH hypothesis. (E) A proto-ribosome has a different enzymatic activity from that of peptidyl transferase. AA: amino acid. Ribozyme (black curved line) activity (nucleotide center: black hexagon) is stimulated by two different amino acids (colored circles) as cofactors. A mutation in the black ribozyme resulted in peptide ligase activity (red star) and produced catalytic dipeptides that facilitated the activities of red and blue ribozymes as well as those of black ribozymes having peptide ligase activity. (F) Novel concepts presented in this study: (e) Combining previous knowledge on the concepts shown in A(a), C(b), D(c), E(d), and aminoacyl-RNA itself, yields a cofactor of ribozymes. (f) L-amino acid is selectively used for aminoacyl-RNA formation. (g) Schematic diagram of a natural three-subunit ribozyme. The hexagon indicates the catalytic nucleotide center. (h) A three-subunit ribozyme, in which L-aminoacyl-RNA subunit as cofactor is sandwiched between large and small RNA subunits. Detailed descriptions of 2A–2F are presented in the main text.
Several reviews have been published on the dozens of hypotheses describing the origin of the genetic code and translation (Ma, 2010; Koonin and Novozhilov, 2017), of which several are addressed in this study. Although physical relationships among catalytic amino acids, codons and anticodons were systematically examined by the direct RNA templating (DRT) hypothesis (Yarus, 1998), only Arg interacted with corresponding pairs of codons and anticodons (Fig. 2B, left panel). In another physical interaction model, a complex of four nucleotides (C4N) (Fig. 2B, right panel) (Shimizu, 1995) and small C4N hairpin RNA, having the anticodon at the 5′ end and the discriminator (d) and CCA (3′-terminus of tRNA) at the 3′ end, recognize the corresponding amino acid. In the coding coenzyme handle (CCH) hypothesis (Szathmáry, 1993), a catalytic amino acid conjugated with an anticodon interacts with a codon of a ribozyme-based aminoacyl transferase, which acts as a cofactor for other ribozymes (Fig. 2C). In another version of the CCH hypothesis (Kun and Radványi, 2018), ribozymes can coevolve with catalytic amino acids, adenosine monophosphate (AMP)-activated catalytic amino acids, and/or catalytic amino acid-conjugated RNA (Fig. 2D). Although C4N, DRT, CCH and the modified CCH hypotheses partially imply how amino acid-specific aminoacyl-RNAs are synthesized in the RNA world, they do not satisfactorily explain how aminoacyl-RNAs link with the template (codon)-dependent translation system.
It was proposed that the proto-ribosome has a different activity from that of a peptidyl transferase, and its initial enzymatic activity is stimulated by two catalytic amino acids (Wolf and Koonin, 2007). A mutation on a ribozyme generates peptide ligase activity, in which two amino acids are ligated to form a dipeptide. Dipeptides are beneficial for their own function and that of other ribozymes, leading to a positive feedback loop (Fig. 2E). Unfortunately, hypotheses about ribozyme function (Figs. 2B–2E) cannot explain how the Darwinian driving force generates the genetic code among catalytic amino acids and their corresponding codons and anticodons. Taking into account all precedent hypotheses on catalytic amino acids, I hypothesize that an aminoacyl-RNA is a ribozyme cofactor (Fig. 2F(e)), and there is no relationship between amino acids and their corresponding future codons and anticodons.
Organisms often use chiral chemicals. Natural nucleotides in RNA are made from D-ribose; natural amino acids in proteins are L-amino acids. Upon mixing an ‘RNA minihelix’ and an aminoacyl-phosphate-D-oligonucleotide, the RNA minihelix is preferentially aminoacylated with L-amino acids (Fig. 2F(f)) (Tamura and Schimmel, 2004). Using a mirror-image L-oligonucleotide, opposite selectivity is obtained. Thus, L-aminoacyl-RNA was likely used in the RNA world based on prebiotically defined D-oligonucleotides.
There is a three-subunit ribozyme (Fig. 2F(g)) (Doudna et al., 1991). By bottom-up thinking, taking into account all the points raised in Fig. 2, I hypothesize that such a three-subunit ribozyme contains an L-aminoacyl-RNA subunit (as cofactor) that is sandwiched between a large and small RNA subunit (Fig. 2F(h)). If the catalytic nucleotide of the large RNA is stimulated by catalytic aminoacyl-RNA, the three-subunit ribozyme acquires a superior active site, containing a two-component center (Fig. 2F(h)). A top-down approach to understanding extant ribosomes predicts almost the same structure for a multi-subunit ribozyme (Supplementary Fig. S1).
Catalytic amino acid-specific aminoacyl-RNA synthesisGlutamic acid (Glu), aspartic acid (Asp), lysine (Lys), tyrosine (Tyr), His, arginine (Arg), cysteine (Cys) and Ser are general acid–base catalyzers (Nelson and Cox, 2021), making them excellent candidates for cofactors of ancient ribozymes. The descending order of frequency of these eight amino acids in enzymes in the PDB having one catalytic amino acid is as follows: Glu, Asp, Lys, His, Arg, Tyr, Cys and Ser (see Fig. 3B) (Kun and Radványi, 2018); however, this ranking is likely to change in a future database, and does not necessarily reflect that of the prebiotic era. Nevertheless, I used the ranking reported by Kun and Radványi (2018) to formulate one of the possible scenarios in this study. When glutamyl-RNA is inserted between large and small RNA subunits, Glu and its catalytic nucleotide are centered in an active pocket of the ribozyme (Fig. 3A). Instead of glutamyl-RNA, other catalytic aminoacyl-RNAs (asparaginyl-RNA, lysyl-RNA, histidyl-RNA, arginyl-RNA, tyrosyl-RNA, cysteinyl-RNA, and seryl-RNA) can be interchanged with each other in ribozymes, immediately leading to ribozymes containing eight different active sites (Fig. 3B). For instance, representative enzymes in extant metabolic pathways, such as glycolysis, glucogenesis and the citric acid cycle, have Lys, His or Ser in their active site (Supplementary Fig. S2). Because a cartridge-type aminoacyl-RNA subunit could be highly beneficial as a ribozyme cofactor, ribozymes having catalytic amino acid-specific (cis or trans) aminoacyl-RNA synthetase activities (Janzen et al., 2022) could be positively selected by the Darwinian driving force.

Driving force for Darwinian selection led to amino acid selective aminoacylation. (A) Three-subunit ribozyme containing glutamyl-RNA, which is sandwiched by large (black) and small (blue) RNA subunits. Because the ribozyme has a catalytic center made by a nucleotide (hexagon), Glu and the active nucleotide form a twin center. Glutamyl-RNA is accommodated in the proto P-site. (B) Replacing the cartridge in the ribozyme complex instantly creates eight different active centers. Another aminoacyl-RNA (asparaginyl-RNA, lysyl-RNA, histidyl-RNA, arginyl-RNA, tyrosyl-RNA, cysteinyl-RNA and seryl-RNA) can be exchanged with glutamyl-RNA. Amino acids having catalytic activity are ordered by their frequency in the PDB (Kun and Radványi, 2018). Colored circles represent a single amino acid.
I refer to the pocket consisting of a large RNA for the aminoacyl-RNA cartridge (Figs. 2F(h), 4A, 4B and Supplementary Fig. S1B(c)) as the proto P-site, also named the P-site of extant ribosomes (Supplementary Fig. S1B(a)). Gene duplication often accelerates evolution (Ohno et al., 1968). As expected with the proto-ribosome (Huang et al., 2013; Rogers, 2017), internal duplication of the proto P-site in the large RNA of a multi-subunit ribozyme (Fig. 4A) created a proto A-site (Fig. 4B), which is referred to as the A-site of extant ribosomes (Supplementary Fig. S1B(a)). If only one cartridge is inserted into either the proto P- or A-site of the ribozyme, it maintains neutral activity (Fig. 4B) (Kimura, 1969; Ohta, 1976). The three-subunit ribozymes shown in Fig. 4B can be transformed into unknown intermediate states (Fig. 4C), followed by random insertion of two out of eight cartridges (Fig. 4D) or template-directed insertion of two cartridges (Fig. 4E). The random insertion of two of eight cartridges in both proto P- and A-sites could result in ribozyme extinction because of purifying negative selection caused by mis-regulated activity (Fig. 4D). The only way for the ribozymes depicted in Figs. 4B and 4C to survive is through the establishment of template-directed insertion of two cartridges into the ribozyme (Fig. 4E). Accordingly, ribozymes could be positively selected (Fig. 4E) through the creation of a huge catalytic space (Supplementary Fig. S3).

Duplication of the proto P-site created a proto A-site. (A, B) Because the A-site of the extant ribosome is postulated to have been produced by duplication of the P-site, I hypothesized that the proto P-site of the three-subunit ribozyme (A) is duplicated (B). The large RNA subunit has two active nucleotide centers, and an aminoacyl-RNA cofactor might insert into either the proto P- or the A-site. In this case, a mutated ribozyme (B) maintains its original enzymatic activity. (C) Unknown transition states. Although one possible scenario of molecular evolution from “State B or C” to “State E” is shown, how such molecular transitions occurred in the prebiotic era is uncertain. (D) Deleterious ribozymes. Random insertion of two out of eight cartridges into the ribozyme could inactivate enzymatic activity. (E) Template-directed insertion of two cartridges. A codon that encodes two or more different amino acids could be negatively selected because ribozyme activity is mis-regulated. Thus, a codon encoding a single amino acid is positively selected. (F) Extant enzyme. (a) Glu35 and Asp52 are distant from each other in the hen egg white (HEW) lysozyme polypeptide. Protein folding (d) of the polypeptide (a) according to Anfinsen’s dogma (b) and/or AlphaFold (c) creates an active site (e) in the HEW lysozyme containing Glu and Asp (see PDB 1HEW). “>>” indicates much higher catalytic activity.
Although a variety of ribozymes with or without aminoacyl-RNA cartridges could exist in the RNA world, template-directed insertion of two cartridges could occur (Fig. 4E). For instance, if the extant codons for Glu and Asp are applied to a two-cartridge ribozyme (Fig. 4E), only six-nucleotide sequences, such as “GAAGAU”, can specify Glu and Asp in the active pocket of a three-subunit ribozyme (Fig. 4E). This is the first link between the “GAAGAU” genotype and phenotype (position of Glu and Asp in the 3D structure of the ribozyme). In the case of extant enzymes, Glu is separated from Asp in the amino acid sequence. The polypeptide is folded under Anfinsen’s dogma (Anfinsen, 1973) and AlphaFold (Senior et al., 2020), leading to an active site, containing Glu and Asp (Fig. 4F).
The first wave of generating the genetic code based on amino acid catalytic abilityRibozymes containing two cartridges create dozens of different active sites (Supplementary Fig. S3A), which can easily cover the representative active sites of protein enzymes described in biochemistry textbooks (Supplementary Fig. S3B). Because ribozymes containing two cartridges also have two catalytic nucleotides in the large RNA, they can mimic protein enzymes, containing three active nucleotide/amino acid catalytic centers, a metal, and/or a cofactor (Supplementary Figs. S4A–S4D). Ribozymes containing two cartridges can be allosterically regulated (the so-called “riboswitch”; Micura and Höbartner, 2020; Supplementary Fig. S4E). It is noteworthy that one of the postulated inactivation mechanisms for ribozymes containing two cartridges is the translocation of template (Supplementary Fig. S4F). Taking all cases described in Fig. 4 and Supplementary Figs. S3 and S4 into account, the creation of a driving force on the template of a multi-subunit ribozyme leads to the generation of the primary genetic code based on amino acid catalytic activity (Fig. 5A).

The first wave generating the genetic code. (A) Ordering of amino acids with catalytic ability. According to the description in Fig. 3 (Glu (1) to Ser (8)) (Kun and Radványi, 2018), the genetic code was generated in the order shown here. (B) Generation of the Asp codon from the Glu codon. The anticodon (CUU) of Glu interacts with the GAA codon based on Watson–Crick base pairing. According to the wobble base pairing hypothesis (Crick, 1966), the anticodon (CUU) of Glu also interacts with the GAG codon. One point mutation on the anticodon (CUU) of Glu led to the anticodon (CUG) of Asp, which interacts with codons GAC and GAU via Watson–Crick and wobble base pairings, respectively. Thus, simultaneous mutations on both anticodons and codons generated the genetic code for Asp. (C) Possible order of generation of the genetic code. Except for Arg and Ser, catalytic amino acids commonly have two codons. Both Arg and Ser have six codons (colored blue and green, respectively). (D) A summary of Figs. 2, 3, 4, 5B. (a) Evolutionary driving force for eight catalytic amino acid-specific aminoacyl-RNA synthetases for multi-subunit ribozymes, containing one aminoacyl-RNA cofactor. At this stage, there are no codons or anticodons. (b) By contrast, generation of the genetic code is essential for template-dependent insertion of two aminoacyl-RNA cartridges in a multi-subunit ribozyme. Thus, these two independent Darwinian driving forces created proto-transfer RNA (tRNA), which has an amino acid and a corresponding anticodon.
There are millions of possible trajectories for the emergence of the genetic code (Koonin, 2017). Since it was impossible to describe them all, previous studies on the origin of the genetic code have specified some starting points of amino acids and their codes (Supplementary Fig. S5). The extant ranking of amino acids (Fig. 5A) was not necessarily the same in the prebiotic era. Furthermore, the extant codon of GAA for Glu may not have been the same in the prebiotic era. However, to simplify hypotheses about the emergence of a variety of genetic codes, I indicated that the extant ranking (Fig. 5A) and GAA for Glu were the same in the prebiotic world. However, other catalytic amino acids (Asp, Lys, His or Tyr) are also good candidates for the first amino acid incorporated into two-cartridge ribozymes. Of note, the second position of codons for Glu, Asp, Lys, His and Tyr is always adenine (A) (see Figs. 10 and 11). This conjecture was advanced more than 30 years ago as the concept “the code within the codons” (Taylor and Coates, 1989) (Supplementary Fig. S5).
Since the evolution of a tRNA gene through the introduction of a point mutation in an anticodon has been experimentally demonstrated (Saks et al., 1998), one point mutation in an anticodon and subsequent mutation of the template can easily create new ribozyme active sites (Fig. 5B). The frequency of amino acids found in protein enzymes containing one active site could generate the genetic code order shown in Fig. 5C. Importantly, the process of catalytic amino acid-specific aminoacyl-RNA synthesis (Fig. 3B) and generation of the primary genetic code (Fig. 5C) can be selected by distinct driving forces in a temporally different manner (Fig. 5D).
Birth of primitive proto-ribosomesAs noted above, proto-ribosomes can have enzymatic activity other than peptidyl transferase activity (Fig. 2E and Supplementary Fig. S1B(c)) (Wolf and Koonin, 2007). Ribozymes acquired peptidyl transferase activity through mutations (Fig. 6A(a)), leading to an empty cartridge at the proto P-site and dipeptidyl-RNA at the proto A-site (Fig. 6A(b)). Subsequently, secondary mutations inactivated the nucleotide center at the proto A-site (Fig. 6A(b)), leading to the birth of a primitive ribosome (proto-ribosome) (Fig. 6B and Supplementary Fig. S1B(b)). Because peptidyl transferase activity abolishes the original ribozyme activity, it could be a negative effect. On the other hand, peptidyl transferase activity producing template-dependent dipeptides might be beneficial for the RNA world. Thus, proto-ribosomes can survive because of nearly neutral selection (Ohta, 1976).

Birth of the proto-ribosome. (A) (a) According to the hypothesis in Fig. 2E (Wolf and Koonin, 2007), the large RNA subunit acquired peptidyl transferase activity (red star) through mutations. (b) Empty cofactor RNA at the proto P-site and dipeptidyl-RNA at the proto A-site. The original ribozyme activity was abolished by a mutation in the large subunit RNA shown in (a). Because a dead ribozyme is beneficial in the RNA world (see Fig. 7B), the catalytic nucleotide at the proto A-site (black hexagon) was inactivated (gray hexagon), leading to a primitive proto-ribosome (B). (B) Among the components of ready-made ribozymes, the large RNA subunit, small RNA subunit, aminoacyl-RNA subunit (cofactor) and template are called rRNA(L), rRNA(S), tRNA and mRNA, respectively.
Under normal thermodynamic conditions, insertion of tRNA into the A-site and the translocation step naturally occur even in extant ribosomes without protein-based translation elongation factors (Noller, 2012). Random peptide synthesis occurs in a distributed manner (Fig. 7A). Upon acquiring translocation ability, a template-directed short peptide is synthesized in a successive manner (Fig. 7B). All dipeptides (e.g., Ser-His in Fig. 2A) and short peptides are expected to display far lower enzymatic activities than pure RNA ribozymes and ribozymes containing two cartridges (Fig. 7C). This raises the question of what driving force generates additional genetic codes for non-catalytic amino acids.

Successive mRNA-dependent translation. (A) Random synthesis of a short peptide. Without translocation ability, both aminoacyl-tRNA and peptidyl-tRNA are randomly inserted into the six nucleotide coding positions of the P- and A-sites in the postulated ribosomes, producing a variety of peptides. (a) When peptidyl-tRNA and aminoacyl-tRNA are inserted into the P- and A-site, respectively, elongation of one amino acid occurs. (b) When only peptidyl-tRNA is inserted into the P-site, a peptide is released. For instance, the Ser-His dipeptide is beneficial in the RNA world (Fig. 2A). (B) Successive mRNA-dependent peptide synthesis. Altered elongation (a, b) and extant ribosome-like three-nucleotide translocation of mRNA (b, c). Peptidyl-tRNA at the A-site (b) is shifted to the P-site (c). (d) Inserting another aminoacyl-tRNA at A-site enables the peptide to elongate in the next cycle (e). (C) Catalytic ability of short peptides. As described in Fig. 2A, the catalytic activity of any type of short peptide is lower than that of two-cartridge-type ribozymes and pure ribozymes. Thus, the catalytic activity of peptides was insufficient for Darwinian selection to drive the expansion of the genetic code.
A proto-ribosome is expected to be a pure ribozyme. However, extant ribosomes of Bacteria, Archaea and Eucarya have more than 50 proteins (Supplementary Figs. S1 and S6A). The scenario shown in Supplementary Fig. S6 (coevolution of ribozyme with peptide/folded protein) has been repeatedly proposed (Lahav et al., 2001; Goldman et al., 2010).
Universal ribosomal proteins are listed in Supplementary Figs. S7A and S7B. α-helixes, β-sheets and intrinsically disordered regions (IDRs) (blue arrows in Supplementary Figs. S7A and S7B) are often seen in ribosomal proteins. Amino acid sequences of examples of ribosomal protein IDRs are shown in Fig. 8A. It is noteworthy that Lys, Arg and Gly (Fig. 8B) are much more abundant than Pro. Because the IDR of ribosomal proteins penetrates into rRNA, Lys and Arg interact with rRNA, and Gly is required for bending of the polypeptide. Among these three amino acids, Lys and Arg are already incorporated into the primary genetic code (Fig. 5).

The second wave of genetic code generation based on IDR preference. (A) Amino acid sequence of the IDR in ribosomal proteins in Supplementary Figs. S7A and S7B. Catalytic amino acids are in red (Figs. 3 and 5), amino acids preferentially found in the IDR are in orange (Fig. 8C), and amino acids preferentially found in the internal region of folded proteins are in green (Figs. 8C and 9). The other amino acids in the sequence are in black (Figs. 8 and 9). (B) Order of preference of amino acids in the IDR of ribosomal proteins. Twenty amino acids are ordered according to their frequency in the IDR of ribosomal proteins (A). The number associated with each amino acid is summated from (A). (C) Preferential order of amino acids in IDRs. Twenty amino acids are ordered according to their frequency of occurrence in IDRs in the PDB (Uversky, 2015). The orange-colored amino acids are numbered, which indicates the predicted incorporation order during the expansion of the genetic code. (D) One-letter codon changes. One letter of the Ser codon changed, which gave rise to the Pro, Ala and Thr codons. The Gly and Gln codons were generated from one-letter changes in the Ala and Glu codons, respectively. (E) Peptides (intrinsically disordered proteins; IDPs) facilitate ribozyme function. The IDP can stimulate all types of ribozymes ((a) and (b)). (F) The IDR forms a structure upon interacting with a ribozyme. Upon binding to RNA and/or a protein, the IDR can form an α-helix, a β-strand and many other structures. (G) If alanyl-RNA is inserted into a two-cartridge-type ribozyme without changing its code (for instance, the same codon for Ser), ribozyme activity is instantly abolished.
The driving force for a second wave of generating the genetic code could be a preference for the IDR. According to the PDB, the frequency of each amino acid in IDRs is ordered from proline (Pro) to Cys (Fig. 8C) (Uversky, 2015). Possible pathways generating additional genetic codes are tentatively ordered by amino acid preference in the IDR (Figs. 8C and 8D) (Uversky, 2015). Of note, the preference of each amino acid in the IDRs shown in Figs. 8A and 8B will be re-visited (see Fig. 11). The IDR interacts with ribozymes and ribosomes (Fig. 8E(a) and (b)), and then forms an α-helix, a β-strand and a variety of other structures (Fig. 8F). Importantly, if Ala uses the same code for Ser (UCU) (Fig. 8D), aminoacyl-RNA for Ala instantly eliminates the activities of 15 types of two-cartridge ribozymes (Fig. 8G and Supplementary Fig. S8). Thus, a new amino acid should acquire its own code.
Thirteen amino acids are sufficient for protein foldingThe predicted transition from peptide world to folded protein world is summarized in Supplementary Figs. S9 and S10. Because efficient protein folding requires hydrophobic amino acids, the third wave of genetic code expansion must have incorporated codons for these hydrophobic amino acids. According to the PDB, Met, Asn, Val, His, Leu, Phe, Tyr, Ile, Trp and Cys tend to be internally located in folded proteins rather than in the IDR (Figs. 8C and 9A) (Uversky, 2015). Among these amino acids, His, Tyr and Cys were already incorporated into the genetic code during the first wave (Fig. 5). A minimum set of amino acids for folding of the ancestral nucleoside diphosphate kinase Arc1 was experimentally determined as two sets (Set 1 and Set 2) composed of 13 amino acids (Fig. 9B) (Shibue et al., 2018). Asn, Val and Leu, which are common residues in the two sets, could be the first amino acids acquired during the third wave of genetic code expansion (Fig. 9C(a) and (b)). Phe (Fig. 9C(c)) and Ile (Fig. 9C(b)) were then incorporated into the genetic code. Among the five amino acids (Cys, Gln, Thr, Met and Trp) that are not essential for protein folding (Fig. 9B), Cys, Gln and Thr were incorporated into the genetic code during the first and second waves (Figs. 5 and 8), leaving Met and Trp.

The third wave of genetic code generation based on protein folding preference. (A) Amino acids in the lower row are required for protein folding. Amino acids in green are incorporated into the genetic code during the third wave, and their associated numbers indicate the postulated incorporation order into the genetic code. (B) Thirteen amino acids are sufficient for Arc1 activity. Comprehensive mutational analysis of the Arc1 enzyme reveals that 13 amino acids from either Set 1 or Set 2 are sufficient to maintain Arc1 activity at a similar level to that of the wild type. Thus, the amino acids common to Set 1 and Set 2, such as Asn, Leu and Val, are preferentially incorporated into the genetic code. Subsequently, Phe and Ile in Set 2 are incorporated. (C) One-letter changes that lead to new amino acid codons. (a) A one-letter change in the Asp codons leads to the Asn codons. (b) Postulated order in which three branched-chain amino acids (Val, Leu and Ile) are generated by a one-letter codon change. (c) A one-letter change in the Tyr codons leads to the Phe codons.
In the RNA–peptide folded protein world, there are three types of RNA, namely mRNA (Fig. 10A(a)), functional RNAs (non-mRNA) (Fig. 10A(b)), and (–)-strand RNAs (Fig. 10A(c)), which are replicative intermediates for (+)-mRNA, and a variety of other functional RNAs. Because the ribosome has to discriminate among a variety of RNA types before initiating translation, only the (+) mRNA initiation codon AUG, which corresponds to Met, could coevolve with initiation factors, such as IF2 (Fig. 10B and Supplementary Fig. S9B). One- or two-nucleotide degradation at the 5′ end of a leaderless-type mRNA (Fig. 10A(a)(1)) could easily lead to a frameshift mutation. To overcome this problem, a Shine–Dalgarno SD (–) leader (+) mRNA (Fig. 10A(a)(2)) emerged. During the enlargement of mRNA (Supplementary Fig. S10D), operon-type mRNA could evolve, which requires both the SD sequence and stop codons (Fig. 10A(a)(3)). Among UAA, UAG, UGA and UGG, Trp, which is the 20th amino acid, incorporates into UGG as part of the genetic code (Fig. 10C(a)) to enrich protein diversity. The three codons that are unassigned could interact with empty-tRNA containing AUU, AUC or ACU (Fig. 10C(b)). These empty-tRNAs were replaced with protein-based releasing factors, mimicking tRNA structure (Fig. 10C(c)) (Toyoda et al., 2000).

Origin of initiation and stop codons. (A) A variety of RNA types in the RNA world. (a) There are three types of mRNA in Bacteria and Archaea (Wen et al., 2021): (1) leaderless mRNA, (2) Shine–Dalgarno (SD)(−)-leader(+) mRNA and (3) SD(+)-leader(+) mRNA. The relative amount of type (3) mRNA is higher in organisms that grow rapidly (Wen et al., 2021). It is noteworthy that (−)-strand mRNAs also exist as replicative intermediates of (+)-strand mRNA. (b) A variety of non-mRNA functional RNAs. (c) Replicative intermediates of all RNAs in (a) and (b). (B) Origin of the initiation codon. One of the codons for Ile was transformed to an initiation codon (AUG) that encodes Met. (C) Stop codons and codons for Trp. (a) Among the original Trp codons, four (UAA, UAG, UGA and UGG) were left. Of these, UGG was assigned by chance as the codon of the 20th amino acid, Trp. Although Trp is not required for Arc1 activity (Fig. 9B), its introduction could enrich protein diversification. (b) Putative releasing factors made by RNA. Empty proto-tRNA with the anticodons AUU, AUC or ACU could act as releasing factors in the RNA world’s translation system. (c) A protein-based releasing factor based on the scheme shown in (b). Such protein-based releasing factors emerged by mimicking RNA-based releasing factors (PDB; 1EH1). (D) Eight different driving forces for the generation of the genetic code. (E) Color-coded codons of all 20 amino acids. Each codon is colored based on the colors of the driving forces shown in (D).
Figures 3, 4, 5, 6, 7, 8, 9, 10 reveal seven different driving forces to generate the genetic code (Fig. 10D). An eighth driving force that fine-tunes the genetic code could have occurred before the establishment of the LUCA (see Fig. 11 and Supplementary Figs. S11 and S12). Such a fine-tuning mechanism includes horizontal transfer of code fragments among protocells (the pre-LUCA) (Woese, 2002; Vetsigian et al., 2006; Froese et al., 2018). A table of the genetic code (Fig. 10E) is colored based on the concepts presented in Fig. 10D.
Genetic code variants dictate the ancient process of generating order in the genetic codeThe final driving force generating the genetic code (purple arrow in Fig. 10D) is a process that fine-tunes the code (Fig. 11A) during the transition from the RNA world to the protein world (Supplementary Figs. S11 and S12). The standard genetic code (SGC) (Table in Fig. 11B) can sometimes be naturally modified with variant codes (Fig. 11B(a)–(g), outside the Table) (Koonin and Novozhilov, 2017), implying reversibility of the genetic code. UUA (for Leu) and UCA (for Ser) changed to stop codons (Fig. 11B(a)), and therefore could correspond to secondarily acquired codons for each of the amino acids described in Fig. 11B(d) and (e). As shown in Fig. 11B(b) and (c), the stop codons UAA, UAG and UGA changed into codons for a variety of amino acids, such as Trp. Such changes indicate the lack of physical and chemical reasons explaining the origin of stop codons, and the usefulness of using UAA, UAG and UGA for coding amino acids (e.g., UGG for Trp; Fig. 10C). CGU, CGC, CGA and CGG for Arg changed to unassigned (Fig. 11B(d)), suggesting that these are secondarily acquired codons, with AGA and AGG as the primary codons. AGA, which originally coded for Arg, changed to code for Ser (Fig. 11B(d)). Moreover, AGG, which is another ancient codon for Arg, changed to code for Ser and changed further to code for Gly (Fig. 11B(d)). Taking into account the code variation patterns of Arg, the process of generating order in the ancient code can be reconstructed (Fig. 11B(d)) among multiple pathways (Figs. 8 and 9).

Genetic code variants. (A) Eight different driving forces generating the genetic code. Enlarged view of Fig. 10D. The purple arrow is the same as in Fig. 10D and Supplementary Fig. S12A. (B) Reconstructing the ancient pathway that generated the genetic code. The table represents the standard genetic code (SGC). There are many genetic code variants in a number of organisms. Such variants are presented in purple-shaded boxes (a)–(g) adjacent to the SGC table. A comparison of the SGC table between Figs. 10E and 11B reveals unshaded areas (i.e., with white backgrounds) in parts of the codons for Leu, Ser, Arg and Gly. As explained in the text, I concluded that the white backgrounds represent secondary codons for Leu, Ser, Arg and Gly. The number associated with each amino acid in (e) is based on the frequency of its appearance in the IDRs, as shown in Fig. 8B. The colored open arrows in the purple-shaded boxes are related to the driving forces depicted in (A). The thin blue and red arrows in (d) and (e) represent the postulated order in which the ancient pathway generated the genetic code as judged by extant genetic code variants. Note that the blue and red arrows differ from the black arrows in Figs. 5C, 8D and 9C; on the other hand, the thin black arrows in (d) and (e) are the same as those shown in Figs. 5, 8 and 9.
CUU, CUC, CUA and CUG, which code for Leu, often changed to code for Thr and Ser (Fig. 11B(e)), even though such changes required two-letter modifications (Fig. 11B(e)). Such observations indicate that the ancient generating order of the genetic code transitioned from Ser/Thr to Leu. Because Gly often occurs in the IDR of universal ribosomal proteins (Figs. 8A and 8B), it acquired the secondary codons GGA and GGG (Fig. 11B(e)). Similarly, Arg is often used in the IDR of universal ribosomal proteins (Figs. 8A and 8B), in addition to its catalytic function (Figs. 3 and 5). Thus, Arg also acquired the secondary codons, CGU, CGC, CGA and CGG (Fig. 11B(e)). A similar scenario also applies to secondary codons of Ser, namely UCU, UCC, UCA and UCG. The transition from Ala to Ser (Fig. 11B(e)) is supported by the results of analyses of the Escherichia coli genome (Inouye et al., 2020). Moreover, the postulated secondary codons for Leu, Ser and Arg (Fig. 11B(e)) agree with those proposed in a previous study (van der Gulik and Hoff, 2011).
The codons of Ser or Thr could generate the Leu codons CUU, CUC, CUA and CUG (Fig. 11B(e)). Because Leu could be first incorporated into the genetic code for efficient protein folding and eventually crossed fitness valleys via double substitutions within the Ser or Thr codons, its usefulness expanded (Belinky et al., 2019). Furthermore, the usefulness of Leu can be further illustrated through the production of the secondary codons UUA and UUG, leading to the recruitment of other types of branched amino acids, such as Val and Ile, into genetic code (Fig. 11B(e)). AUU, AUC, AUA and AUG are the expected initial codons for Ile. Among these four codons, the driving force that created the initiation codon, AUG, occurred by chance (Fig. 10B). Thus, AUA can play a role as an initiation codon, just like AUG (Fig. 11B(f)).
By hypothesizing the existence of one-cartridge (Fig. 12A(a)) and two-cartridge ribozymes (Fig. 12A(b)), I have been able to fill tentatively the gaps (bidirectional red arrow in Fig. 1B(b)) in the understanding of the symbolic “red rocks” (Fig. 1A(b)), which supports the integrity of the pre-LUCA. Thus, the LUCA emerged ~3.8–3.9 billion years ago under the laws of physics, chemistry and biochemistry. During the generation of the genetic code, a “frozen accident” occurred before the emergence of the LUCA (Crick, 1968) (Fig. 12B). If the hypothesis in Fig. 12A is correct, the updated “frozen accident” defined in this study could have coincided with the appearance of the first two-cartridge ribozyme (Figs. 5 and 12B).

Filling two missing large rocks in the origin of life. (A) Two large rocks supporting the transition from the RNA world to the protein world. (a) One-cartridge (green rectangle) and (b) two-cartridge ribozymes (pink rectangle) as large rocks can be inserted as Cairns-Smith’s red rocks (Fig. 1A(b)), supporting construction of the gray arch, based on the conclusions of this study. Thus, the bidirectional red arrow in Fig. 1B(b), symbolizing the difficulty of understanding the origin of the genetic code and translation system, can be replaced with these two missing large rocks. Molecules (c)–(e) have been synthesized in vitro (see Fig. 1B). If the theory on the genetic code raised in this study is to be proved correct, artificial reconstruction of one-cartridge (a) and two-cartridge ribozymes (b) is crucial. Dissection and reconstruction of extant complicated ribosomes will be required for elucidating the molecules depicted in (a) and (b). Progress in ribosome research supports the hypothesis generated in this study. The function of extant complicated ribosomes can be separated into small pieces and primordial small RNA pocket-like segments made by RNA-mediated catalysis of peptide bond formation in vitro (Xu and Wang, 2021; Bose et al., 2022). Top-down and bottom-up approaches in ribosome research on several RNAs and aminoacyl-RNAs should enable the in vitro reconstruction of the molecules denoted in (a) and (b). (B) “Frozen accident” in this study. Eight driving forces generating the genetic code are the same as those in Figs. 10 and 11. (a) and (b) represent the timing of the first appearance of one-cartridge and two-cartridge ribozymes, respectively. Although Crick’s “frozen accident” pointed to the completion of the extant genetic code (Crick, 1968), I propose an updated “frozen accident” event, in which the first catalytic amino acid with its codon “NAN” (‘N’ means any ribonucleotide) was recruited into a two-cartridge ribozyme by chance in the prebiotic era (see Fig. 5).
The author declares that he has no known competing financial interests or personal relationships that could appear to influence the work reported in this paper.
I thank Ms. M. Seki for illustrating some of the figures. This study was financially supported by the Tohoku Medical and Pharmaceutical University, whose founding spirit is “We will open the gate of truth”; thus, I wish to extend my gratitude to Dr. M. Takayanagi, president of the University.